Supervised and Unsupervised Anomaly Detection Explained
Supervised anomaly detection is an approach of anomaly detection where predefined algorithms are used to analyze datasets and identify irregularities or outliers; while unsupervised anomaly detection is the use of generalized algorithmic models to identify patterns and recognize deviations in large and/or complex datasets. This article discusses supervised and unsupervised anomaly defection approaches, as follows;
-Unsupervised Anomaly Detection
Supervised Anomaly Detection
Supervised anomaly detection is a type of anomaly detection in machine learning, that depends on predefined algorithms that have been used to train artificial intelligence systems.
The use of supervised approach for anomaly detection, is most common for rule-based recognition of outliers, especially for highly predictable and repetitive multivariate dataset patterns.
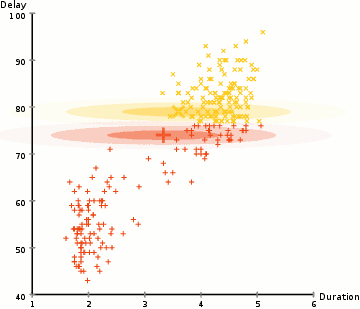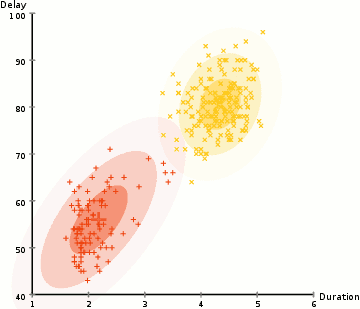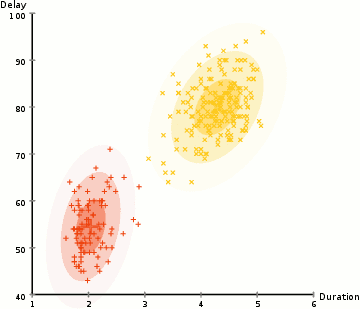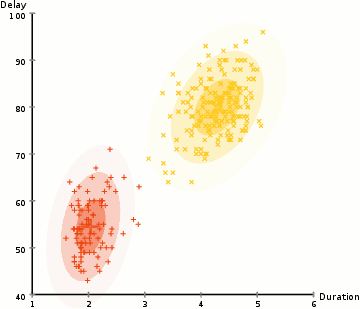
Generally, outlier detection (OD) is an unsupervised procedure, because of the unusual nature of outliers with respect to the normal dataset trends, especially when data is visualized based on multiple variables (multivariate visualization) [2].
Supervised anomaly detection is still possible and can be effective, but its use is not recommendable where datasets are of high volume, complexity, or are defined by several multiple criteria.
It can also be more demanding in terms of resources and maintenance, as engineers are required to continuously assess and modify algorithms.

Unsupervised Anomaly Detection
Unsupervised anomaly detection is the practice of analyzing large amounts of anomalous and/or unlabeled data to identify areas of dis-uniformity, without using any predefined algorithm [3].
The approach used in unsupervised anomaly detection is based on pattern-matching data-trend visualization; where data points are evaluated in clusters to identify general patterns of shapes, so that all outliers are identified as anomalies and used to diagnose a possible drawback [1].
Unsupervised approach is better for anomaly detection, than supervised approach, because such tasks often involve multiple variables and relatively-high complexity, so that a definite, rule-based or supervised approach may not be effective in many cases [5].
Another positive side of unsupervised anomaly detection is its ability to be functional on a passive basis, so that both real-time (active) and retrospective (passive) techniques are usable under this approach [4]. This brings a lot of flexibility, versatility and relative ease into anomaly detection.
Supervised Vs Unsupervised Anomaly Detection: Summary of Difference between Supervised and Unsupervised Anomaly Detection in Machine Learning
The main difference between supervised and unsupervised anomaly detection is the approach involved, where supervised approach makes use of predefined algorithms and AI training, while unsupervised approach uses a general outlier-detection mechanism based on pattern matching.
Unsupervised anomaly detection is achieved using versatile, general-purpose algorithmic models. For supervised anomaly detection, the models used are more specific and have a narrower range of possible application.
Supervised approach is less-optimal or suitable for anomaly detection because of its predefined and specific framework; whereas unsupervised approach is more flexible and adaptable, so that it can be used to detect anomalies in datasets at various levels of complexity, and in various contexts.
The table below summarizes the difference between supervised and unsupervised anomaly detection;
Comparison Criteria | Supervised A.D. | Unsupervised A.D. |
Relative complexity | Low | High |
Framework | Predefined | Generalized |
Functionality | Mainly active | Active, passive |
Relative Suitability | Low | High |

Anomaly Detection Algorithms
Machine learning algorithms that are used for anomaly detection are;
1). Local Outlier Factor (LOF)
2). K-Nearest Neighbor (k-NN)
3). K-means
4). Adaptive Resonance Theory (ART)
5). C-means
6). Self-organizing Maps (SOM)
7). Support Vector Machine (SVM)
8). Expectation-maximization Meta-algorithm (EM)
9). DBSCAN
10). Isolation Forest Model
11). Hypothesis Tests-based Analysis
12). Autoencoders
Conclusion
The difference between supervised and unsupervised approach is in their approaches, functionality and usability, where unsupervised is more flexible, versatile and suitable; and makes use of a more generalized algorithmic framework than supervised anomaly detection.
Machine learning algorithms that are used for anomaly detection are; Local Outlier Factor (LOF), K-Nearest Neighbor (k-NN), K-means, Adaptive Resonance Theory (ART), C-means, Self-organizing Maps (SOM), Support Vector Machine (SVM), Expectation-maximization Meta-algorithm (EM), DBSCAN, Isolation Forest Model, Hypothesis Tests-based Analysis, Autoencoders.
References
1). Goldstein, M.; Uchida, S. (2016). "A Comparative Evaluation of Unsupervised Anomaly Detection Algorithms for Multivariate Data." PLoS ONE 11(4): e0152173. Available at: https://doi.org/10.1371/journal.pone.0152173. (Accessed 3 February 2023).
2). Pascual, Á. F.; Bella, J.; Dorronsoro, J. R. (2022). "Supervised Outlier Detection for Classification and Regression." Neurocomputing 486(2). Available at: https://doi.org/10.1016/j.neucom.2022.02.047. (Accessed 3 February 2023).
3). Wilmet, V.; Verma, S.; Redl, T.; Sandaker, H.; Li, Z. (2021). "A Comparison of Supervised and Unsupervised Deep Learning Methods for Anomaly Detection in Images." Available at: https://www.semanticscholar.org/paper/A-Comparison-of-Supervised-and-Unsupervised-Deep-in-Wilmet-Verma/4588b87fcec20e40761feb0c4bfce2cb96667d0a. (Accessed 3 February 2023).
4). Zeufack, V.; Donghyun, K.; Seo, D-H.; Lee, A. (2021). "An Unsupervised Anomaly Detection Framework for Detecting Anomalies in Real Time through Network System’s Log Files Analysis." Available at: https://doi.org/10.1016/j.hcc.2021.100030. (Accessed 3 February 2023).
5). Zhang, C.; Liu, J.; Chen, W.; Shi, J.; Yao, M.; Yan, X.; Xu, N.; Chen, D. (2021). "Unsupervised Anomaly Detection Based on Deep Autoencoding and Clustering." Hindawi, Security and Communication Networks 2021. Available at: https://doi.org/10.1155/2021/7389943. (Accessed 3 February 2023).