5 Data Mining Techniques Explained
Data mining techniques are; classification, regression, association, clustering, and correlation.
This article discusses data mining techniques, as follows;
1). Classification (as one of the Data Mining Techniques)
Classification techniques in data mining are techniques which are used to categorize raw data into distinct groups with common attribute(s) that can help to extract meaningful and usable information from the data.
An example of classification is the assignment of a label to all image-related data in a large database. Such an operation can help extract information from large volumes of audio and visual data collected in real-time from smart devices in a system like a self-driven electric vehicle.
The above instance shows how data mining can play an instrumental role in other conceptual fields like machine learning and artificial intelligence, through the classification technique.
Classification works by analyzing data using a pre-designed algorithm that assigns a classifier to data points based on their attributes [8]. These attributes could range from format-related to size-related, among others.
With classification, multiple functions such as anomaly detection in datasets can be achieved. This means that the technique is not only useful for data mining or processing, but can be used for a holistic assessment of large data volumes, as well as for data security.
2). Regression
Regression technique in data mining is a problem-solving approach that is used mainly to forecast the values of data points based on functional, numeric relationships observed in a dataset.
An example of regression technique being used in data mining, is the prediction of a target variable like the required dimensions of sections of civil structures in construction; or the forecasting of prices in market analysis.
Classification and regression techniques differ based on their functional context; where classification technique falls under descriptive method of data mining, and regression technique falls under predictive method.
Regression is particularly recommendable and effective where the problem involves a range of values that are continuous and derived from a similar source(s) or function(s).
The technique adopts variables x, y and z, in order identify the relationships between such variables.
Regression may be used in the form of linear, logistic or polynomial regression, among others.
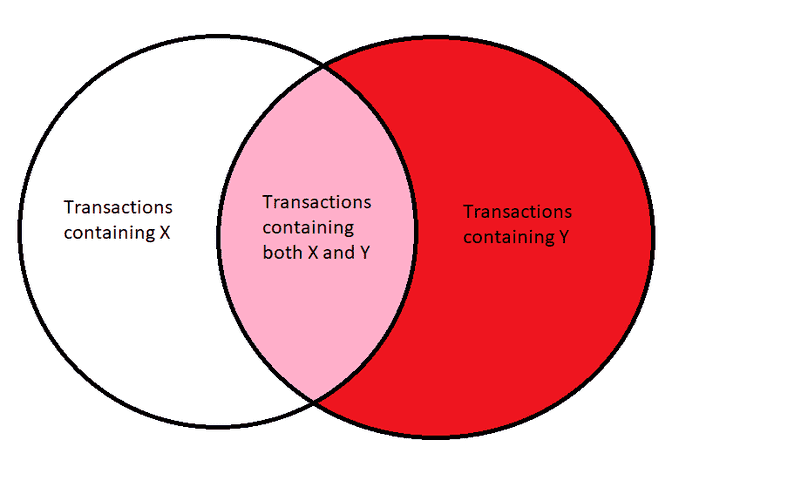
3). Association (as one of the Data Mining Techniques)
Association technique in data mining involves extracting information from large datasets by identifying the dependencies between variables or data points that occur within the same set, group or category.
The use of this technique is facilitated by algorithms that analyze data to identify dependency-patterns and develop models based on such patterns, which are called association rules.
Steps in the use of association rules for data mining are; data skimming, frequency assessment, association ruling, and information extraction (through pattern identification/analysis). These steps help to sift through large volumes of data to spot frequently-occurring patterns and create association rules that can help understand the data and transform it to usable information.
Although correlation is a different technique, it is not uncommon for association to be described as a form of correlation, due to the similarity in their essence and application [3].
Association and correlation in data mining are different in that association focuses on identifying relationships between data points on a broad and holistic scale, while correlation connects specific data points to each other, based on distinct shared attributes or dependencies.
In correlation, variables are treated with more individuality, specification or importance, so that the outcome of using this technique is information that highlights specific trends between specific variables, which could be ascending or descending trends [1].
Based on the above explanation, association is better used where the volume of data is particularly large, and/or there is no need for a high level of specification in the results.
Association also differs from clustering by identifying trends based on co-occurrence of data points; while clustering identifies trends based on attribute-similarity.

4). Clustering
Clustering technique in data mining is a mode of analysis that groups data points from a large set or database, into smaller categories called 'clusters', within which the data points are highly similar to each other, compared to other variables in the overall database [4].
There are various methods of clustering in data mining, which include; hierarchical, grid-based, density-based, model-based, and partitioning methods.
Clustering is particularly useful where the goal is to generate models that help simplify a large dataset, for easy interpretation [2].

5). Correlation (as one of the Data Mining Techniques)
The correlation technique in data mining is a mode of data analysis that extracts useful information from large volumes of raw data by identifying distinctive relationships between specific variables.
Like association, correlation technique reveals dependencies between variables [9], and uses these dependencies to understand and even to predict dynamic trends in datasets [7].
Correlation is used in data mining to simplify the understanding and knowledge-gleaning process for large and/or complex data.
Because of its versatility, correlation technique is applicable across a broad range of industries and roles where databases are used [6].
Types of correlation techniques are; linear, non-linear, partial, simple, positive and negative techniques.
Conclusion
Data mining techniques are;
1. Classification
2. Regression
3. Association
4. Clustering
5. Correlation
References
1). Altman, N.; Krzywinski, M. (2015). "Association, correlation and causation." Nat Methods 12, 899–900 (2015). Available at: https://doi.org/10.1038/nmeth.3587. (Accessed 20 March 2023).
2). Berkhin, P. (2006). "A Survey of Clustering Data Mining Techniques." In: Kogan, J., Nicholas, C., Teboulle, M. (eds) Grouping Multidimensional Data. Springer, Berlin, Heidelberg. Available at: https://doi.org/10.1007/3-540-28349-8_2. (Accessed 20 March 2023).
3). Diwate, R. (2014). "Data Mining Techniques in Association Rule : A Review." Available at: https://www.researchgate.net/publication/282651888_Data_Mining_Techniques_in_Association_Rule_A_Review. (Accessed 20 March 2023).
4). Garima; Gulati, H.; Singh, P. K. (2015). "Clustering techniques in data mining: A comparison." 2015 2nd International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 2015, pp. 410-415. Available at: https://ieeexplore.ieee.org/document/7100283. (Accessed 20 March 2023).
5). Patel, H. P.; Patel, D. (2014). "A Brief survey of Data Mining Techniques Applied to Agricultural Data." International Journal of Computer Applications 95(9):6-8. Available at: https://doi.org/10.5120/16620-6472. (Accessed 20 March 2023).
6). Peters, H.; Link, N.; Heckenthaler, T. (2001). "Application of Data Mining Techniques to Find Correlation Between Quality Data and Process Variables." IFAC Proceedings Volumes, Volume 34, Issue 18, September 2001, Pages 193-198. Available at: https://doi.org/10.1016/S1474-6670(17)33205-6. (Accessed 20 March 2023).
7). Rayward-Smith, V. J. (2007). "Statistics to measure correlation for data mining applications." Computational Statistics & Data Analysis 51(8):3968-3982. Available at: https://doi.org/10.1016/j.csda.2006.05.025. (Accessed 20 March 2023).
8). Sagunthaladevi, S.; Raju, B. R. V. (2016). "CLASSIFICATION TECHNIQUES IN DATA MINING: AN OVERVIEW." Available at: https://doi.org/10.5281/zenodo.58513. (Accessed 20 March 2023).
9). Samiullah, M.; Ahmed, C. F.; Nishi, M. A.; Fariha, A.; Abdullah, S. M.; Islam, M. R. (2013). "Correlation Mining in Graph Databases with a New Measure." In: Ishikawa, Y., Li, J., Wang, W., Zhang, R., Zhang, W. (eds) Web Technologies and Applications. APWeb 2013. Lecture Notes in Computer Science, vol 7808. Springer, Berlin, Heidelberg. Available at: https://doi.org/10.1007/978-3-642-37401-2_11. (Accessed 20 March 2023).
