5 Steps in Data Mining Process Explained
Steps in data mining process are; data acquisition, integration, processing (analysis, reduction, transformation) pattern recognition (modeling) and knowledge representation.
This article discusses the steps in data mining process, as follows;
1). Data Acquisition (as one of the Steps in Data Mining Process)
In data mining, data acquisition is the act and process whereby raw data is collected, gathered or sampled from relevant sources, prior to analysis.
The acquisition of data is often carried out by sensors which are incorporated into smart devices.
Functions that are associated with data acquisition in the context of data mining include; data cleaning and filtration, which can be viewed as pre-processing functions [3].
An example of data acquisition in data mining is the gathering of large amounts of physicochemical values by a soil sensor on a site in real-time. Another example is the real-time collection of audio and visual data by sensors in an electric car that is equipped with deep learning capabilities.
The two types of data acquisition are; analog and digital acquisition, while the methods of data acquisition are; direct storage, sharing, copying and merging.
Data sharing is particularly common where the data mining process involves datasets from multiple sources that must be integrated into a single database model [6]. In general, the type or method of data acquisition is tailored to suit specific demands with regards to size, type, and intrinsic attributes of datasets.
2). Data Integration
Data integration is the second main step in the data mining process.
Basically, data integration is the sum total of all functions and operations aimed at converging datasets from multiple sources, and reducing the heterogeneity of these to make them unified, coherent, and analyzable. An example of data integration is the combining of project data from various departments of an organization, in a single database where the data can be effectively managed.
The need for data integration is highest in cases dealing with large amounts of data from multiple sources that have been acquired for a common purpose.
Types of data integration in data mining are; manual integration and algorithmic integration; where the former is suited to cases involving relatively-simple datasets and the latter requires advanced neural network technology to handle large, complex datasets with multiple attributes.
Techniques used in data integration include bulk formatting and consolidation.
Data integration can be a very challenging step in the data mining process, especially for algorithmic integration of data with a high level of heterogeneity. Factors that must be put into consideration in such cases include the need to avoid data conflicts, database corruption, data losses and excessive redundancy.
3). Data Processing (as one of the Steps in Data Mining Process)
Data processing in data mining is the sum total of all functions and operations by which raw data is transformed to make it easier to manipulate or analyze, for the purpose of extracting useful information, from this data.
The words; 'in data mining' are highlighted above because data processing has a slightly different meaning in the context of data mining, than its general meaning in the field of computer science.
Because of the relative complexity, detail and scale of data mining, it is not possible to process data in a single step, or in a few operations. Rather, data processing occurs in multiple phases that are described with different terms in the entire mining process.
So, the term data processing here refers to the key stage in which it becomes feasible to observe trends in raw data that can be used to extract information.
Data processing itself has stages. The stages of data processing (in data mining) are pre-processing, main processing, and post-processing.
Techniques or functions that are used in data processing include reduction, regression, association, and transformation.
At the end of processing, what is left is a transformed database that is more readable. Often, this database contains hierarchical or statistical data clusters, such as those in a decision tree [5].
Types of data processing are; real-time, batch and multi-processing.
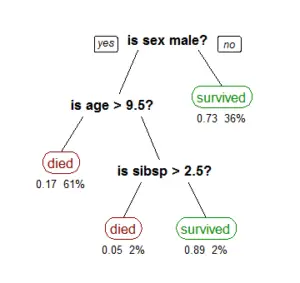
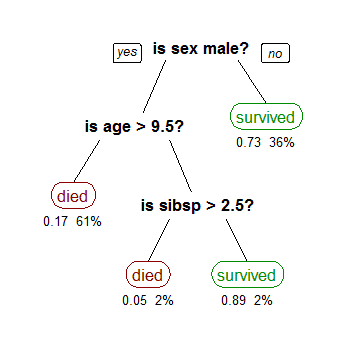
4). Pattern Recognition
Pattern recognition in data mining is the revealing of regularities and distinctive trends in datasets, which can be used to interpret the data, or to predict future data outcomes.
The role of pattern recognition in data mining has grown in importance over the years, mainly as a result of the advancement of artificial intelligence, and the push to develop more-sophisticated machine learning algorithms [4].
Components of the pattern recognition step in data mining include characterization, matching, and trend-continuity evaluation. When implemented, these functional components lead to the development of a data model that reveals links between data points and data clusters.
Pattern recognition is particularly useful for analyzing historical data to extract information that can be used to predict future data points [2].
Types of patterns in data mining include cyclic, linear, and logarithmic.
5). Knowledge Representation (as one of the Steps in Data Mining Process)
Knowledge representation is the final step in data mining, and can be described as the conveyance of extracted information using illustrative models.
As the name implies, knowledge representation has to do with how knowledge derived from data can be presented in an interpretable format [1].
Types of knowledge produced from data mining include numerical, text-based, auditory and pictorial. These can be represented either comparatively or cumulatively using statistical and geometric models like graphs, tables, charts, and hierarchical structures.
Knowledge is important in data mining because it can be used to assess the effectiveness of a particular approach to data management. It also conveys extracted information to the user in an understandable format.

Conclusion
Steps in data mining process are;
1. Data Acquisition
2. Data Integration
3. Data Processing
4. Pattern Recognition
5. Knowledge Representation
References
1). Guangqiang, X.; Yang, L. (2012). "Extension Data Mining Knowledge Representation." Physics Procedia 24:240–246. Available at: https://doi.org/10.1016/j.phpro.2012.02.036. (Accessed 21 March 2023).
2). Halkiopoulos, C.; Koumparelis, A.; Dimou, E.; Theodorakopoulos, L.; Heliades, G. (2019). "Applying Data Mining Techniques for Pattern Recognition in a Knowledge Data Base of Historical Greek Advertising Images." 7th International Conference on Contemporary Marketing Issues. Available at: https://www.researchgate.net/publication/346574861_Applying_Data_Mining_Techniques_for_Pattern_Recognition_in_a_Knowledge_Data_Base_of_Historical_Greek_Advertising_Images. (Accessed 21 March 2023).
3). Lyko, K.; Nitzschke, M.; Ngonga Ngomo, AC. (2016). "Big Data Acquisition." In: Cavanillas, J., Curry, E., Wahlster, W. (eds) New Horizons for a Data-Driven Economy. Springer, Cham. Available at: https://doi.org/10.1007/978-3-319-21569-3_4. (Accessed 21 March 2023).
4). Parasher, M.; Sharma, S.; Sharma, A.; Gupta, J. P. (2011). "ANATOMY ON PATTERN RECOGNITION." Indian Journal of Computer Science and Engineering 2(3). Available at: https://www.semanticscholar.org/paper/ANATOMY-ON-PATTERN-RECOGNITION-Parasher-Sharma/e9f5a8b12712069efff9b83dbfb83796a3ef89af. (Accessed 21 March 2023).
5). Vadim, K. (2018). "Overview of different approaches to solving problems of Data Mining." Procedia Computer Science 123:234-239. Available at: https://doi.org/10.1016/j.procs.2018.01.036. (Accessed 20 March 2023).
6). Wang, W.; Li, H.; Huang, P.; Zhang, X. (2017). "Data acquisition and data mining in the manufacturing process of computer numerical control machine tools." Proceedings of the Institution of Mechanical Engineers Part B Journal of Engineering Manufacture 232(13):095440541771887. Available at: https://doi.org/10.1177/0954405417718878. (Accessed 22 March 2023).
